데이터 마이닝이란 무엇인가?
- 큰 DATASET에서 알려지지 않은, 유효한, 잠재적으로 쓸만한, 이해할만한 패턴의 발견
- DATASET의 분석은 관찰되지 않은 관계를 찾아내고 데이터를 혁신적인 방법(이해가 쉽게 되고, 쓸만한)으로 정리
- 큰 데이터셋에서 반자동적인 분석을 통해 이러한 특성을 가진 패턴을 찾는다.
- Valid: 확실한 데이터인가? (노이즈는 아닌가?)
- Novel: 명확하지 않은 데이터를 명확하게!
- Useful: 그 요소들에 대하여 멋진 행동을 할 수 있는가
- Understandable: 인간이 그 패턴을 보고 쉽게 이해할 수 있는가
- 이러한 패턴을 찾는 과정을 다른 말로 KDD라고 한다.
KDD
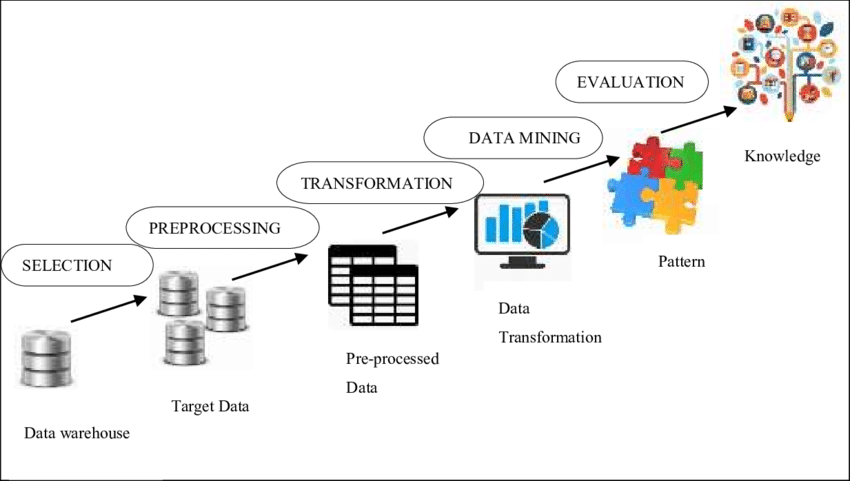 KDD
KDD
KDD란 Knowledge Discovery in Database의 준말로, “데이터로 부터 유용한 지식을 발견하는 전 과정”을 말한다. KDD는 다음과 같은 과정으로 이루어진다.
- 문제 인식 (Problem Formulation)
- 데이터 수집 (Data Collection)
- 전처리 과정 (Pre-Processing, Cleaning)
- 이름이나 주소 값 수정, 동일한 value인데 다른 name이면 수정 (annual, yearly) 등, 중복 삭제, 잃어버린 데이터 채워넣기 (주로 평균값으로)
- 변형 (Transformation)
- 마이닝 업무/방법 선택 (Choosing Minig Task and Mining Method)
- 결과 평가 및 시각화 (Result Evaluation and Visualization)
KDD의 적용: 은행 업무, 고객 관리, 타켓 마케팅, 생산 및 판매 관리
데이터 마이닝
데이터 마이닝은 어떻게 쓰이는가?
- 문제 인식
- 데이터 마이닝 기술로 데이터 변형 → 유용한 정보 추출
- 정보 활용
- 결과 측정
데이터 마이닝 과정
- 입력 이해 (어떤 형식의 입력이 들어오지?)
- 데이터셋 생성 (마이닝 알고리즘에 바로 먹일 수 있도록!)
- 흥미로운 특성 선택
- 데이터 전처리 (Pre-processing)
- 데이터 마이닝 Task와 특정 알고리즘 선택
- 결과 해석, 마음에 안 들면 2로 회귀
데이터 마이닝의 필요성
현실 세계의 데이터는 더럽다.
- 불완전성: 특성 값의 부재, 관심있는 어떤 특성의 부재, 이상한 데이터 포함 등
- 해결법: 잃어버린 값을 채워넣기 (평균, 최소, 최대 등) (Data Imputation)
- 노이즈: 한계 (Outlier) 밖에 존재하는 값 존재 (Error)
- 비일관성: 동일한 값을 가지더라도 다른 방식으로 표현되는 데이터가 있음
쓰레기가 들어가면 쓰레기가 나온다. (Garbage In, Garbage Out) 질 좋은 판단은 질 좋은 데이터에서 나온다. 따라서 데이터 마이닝은 필수적이다!
Data Mining Task
크게 Prediction Tasks (Supervised Learning), Description Tasks (Unsupervised Learning)으로 나뉜다. Prediction은 입력 변수와 정답을 이용하여 알지 못하는 혹은 미래의 값을 예측/예상하는 것이고, Description은 정답 따위 없이 주어진 입력의 특성들을 이용해서 인간 친화적인, 인간이 잘 해석할 수 있는 패턴을 찾아 서술하는 작업이다.
- Prediction Tasks (Supervised Learning)
- Regression (예측, 회귀)
- Classification (분류)
- Description Tasks (Unsupervised Learning)
- Clustering (군집화)
- Association Rule Discovery (연관 규칙 추출)
데이터셋은 두 개의 방향으로 이루어진 매트릭스로 표현할 수 있다. (벡터의 집합)
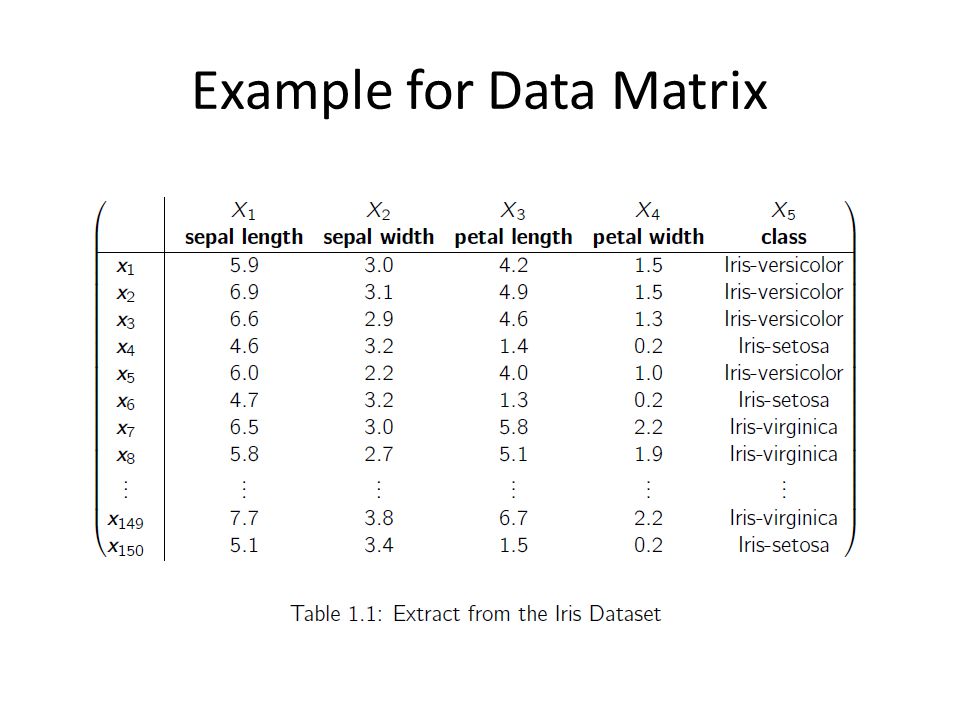 데이터 매트릭스
데이터 매트릭스
각 행은 데이터의 샘플을 나타내고, 각 열은 각 특성을 나타낸다. 만약 인간에 대한 데이터 매트릭스라면, 1행은 1번째 사람을 말하는 것이고, 2행은 2번째 사람을 말하는 것이다. 위 사진을 예시로 들자면, 150명에 대한 데이터 매트릭스이고, 5가지의 특성으로 정리되어 있다.
- 데이터 매트릭스 = 행 백터의 집합 (샘플 벡터의 집합) = 열 벡터의 집합 (특성 벡터의 집합)
요런거 물어보면 헷갈릴 수도 있으니 잘 정리해놓자!
- Number of Sample = Sample Size = n
- Number of Variables = Variables Size = p
- 행 벡터의 관점에서 차원 = p (한 행의 원소의 개수)
- 열 벡터의 관점에서 차원 = n (한 열의 원소의 개수)
- Dimensionality of Data = Length of Each Row Vector = 행 벡터의 길이 = p